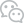订阅
|
绝缘橡胶板 机器之心报道 参与:蛋酱 在深度学习技术的加持下,每一张平面图像都能转换为效果惊艳的3D图像?我突然有一个大胆的想法…… 相比于 2D 内容,能产生身临其境感的 3D 内容仿佛总是会更吸引人。 自从 3D 电影诞生以来,人们从未停止过立体影像的追求。随着近年来 5G 技术的落地,VR 行业也将迎来新的突破,众多游戏玩家和电影观赏者也会因此获得更加新奇的视觉体验。但 VR 场景里 3D 内容的缺乏一直是行业内的一个痛点。 以 3D 电影制作为例,在现阶段,每一部 3D 电影的后期制作都需要投入巨大的资金和人力成本,这些现实条件严重阻碍了 3D 内容的丰富发展。 最近,来自爱奇艺的团队介绍了一种 3D 内容转换的 AI 模型,可通过深度学习技术将 2D 内容快速、批量、全自动地转制成 3D 内容。在减少 3D 内容制作成本的同时,为用户提供更多高质量的立体化影像。 对于任何电影画面来说,都能够转化为 3D 场景: 也可以用来制作立体动态猫片: 这样的效果是如何实现的呢? 模型框架解析 想要把 2D 内容转换为「真假难辨」的 3D 内容,前提是要了解真实人眼的 3D 感知:「为什么在人眼中,世界是立体的?」 对于 3D 介质来说,越是符合真实世界中人眼的 3D 感知,就会越受到用户的喜爱。因此在模型构建上必须符合真实世界的 3D 观感——双目视觉。 图 1:双目相机成像与视差原理。 如图 1 左所示,两个相机拍摄同一场景生成的图像会存在差异,这种差异叫「视差」。视差不能通过平移消除,一个物体离相机越近,视差偏移就越大,反之则越小。 人的左右眼就如同图中的左右相机。在双眼分别获取对应图像后,通过大脑合成处理这种差异,从而获取真实世界的 3D 感知,视差与相机焦距和轴间距间的关系如通过图 1 右所示: 以上为公式(1),其中 z 为物体距离相机的深度,x 为三维映射到二维的图像平面,f 为相机焦距,b 为两个相机间的距离轴间距,x_l 和 x_r 分别为物体在左右不同相机中成像的坐标,因此可知左右图对应像素 x_l 和 x_r 的视差。 同时,考虑到转制的对象为 2D 介质,因此,通过单目深度估计合成新视点的算法原型诞生:通过公式 (1) 可知,假设有一个函数 那么就有: 公式(2)。 通过公式(2)可知,只需要将 图 1 左 作为训练输入,图 1 右 作为参考,即可建立深度学习模型,通过大量双目图片对训练估计出函数 |
|
10 人收藏 |
 鲜花 |
 握手 |
 雷人 |
 路过 |
 鸡蛋 |
收藏
邀请









 654人
654人